تا به حال برای استفاده از متا تگ Robots.txt و The Robots موارد امنیتی را در نظر گرفته اید؟
دانستن تفاوت میان فایل Robots.txt و تگ <META> ی Robots برای سئو و همینطور امنیت حیاتی به نظر می رسد.به علاوه این قضیه می تواند تاثیر بسزایی بر حریم امنیتی وب سایت شما و همینطور مشتریان داشته باشد.ابتدا به معرفی فایل Robots.txt و تگ <META> ی Robots می پردازیم :
Robots.txt
این فایل، فایلی است که شما در یک دایرکتوری سطح بالا از وب سایت خود قرار می دهید ، در همان پوشه ای که یک homepage استاتیک قرار میگیرد.در داخل این فایل، می توانید با رد کردن نام فایل ها و دایرکتوری ها ، به موتور های جستجو یاد بدهید که محتوا را نخزند.در دستورالعمل این فایل دو قسمت وجود دارد ، کاربر عامل و یک یا دستورالعمل های رد شده ی بیشتر.
کاربر عامل یک یا همه ی عنکبوت های وب را شناسایی می کند . منظور ما از Web Crawlers همان Google و Bing است ،اگرچه یک عنکبوت از هرجایی می تواند بیاید،نه فقط موتور های جستجو و در حال حاظر تعداد زیادی از آن ها در حال خزیدن در اینترنت هستند.
در این جا یک فایل ساده ی robots.txt قرار دارد که به Web Crawler ها می گوید تار تنیدن در هرجایی مشکلی ندارد!
User-agent: * Disallow:به منظور منع کردن همه موتور های جستجو از خزیدن در تمام قسمت های یک وب سایت از کد زیر استفاده کنید :
User-agent: * Disallow: /تفاوت این دو در “/” بعد از Disallow است که به پوشه ی اصلی ( root ) و هرچیزی که در داخل آن وجود دارد اشاره می کند ( پوشه ها و فایل های زیر مجموعه ).
Robots.txt کاربرد های متعددی دارد.شما می توانید تمام پوشه های زیرمجموعه یا فایل های جداگانه را رد کنید.همچنین می توانید عنکبوت موتور های جستجوی خاصی مانند Googlebot و Bingbot را منع کنید.موتور های جستجو حتی Robots.txt را گسترش دادند تا یک دستورالعمل Allow ،نام پوشه یا فایل مطابق الگو و نقشه ی سایت XML را مشمول کنند.
در این جا یک فایل robots.txt از SEOmoz می بینیم که به قشنگی گسترش داده شده است :
#Nothing interesting to see here, but there is a dance party #happening over here: http://www.youtube.com/watch?v=9vwZ5FQEUFg User-agent: * Disallow: /api/user?* Disallow: Sitemap: http://www.seomoz.org/blog-sitemap.xml Sitemap: http://www.seomoz.org/ugc-sitemap.xml Sitemap: http://www.seomoz.org/profiles-sitemap.xml Sitemap: http://app.wistia.com/sitemaps/2.xmlکاری که این فایل از انجام دادن آن ناتوان است نگه داشتن فایل ها به دور از دست فهرست های موتور های جستجو است و تنها کاری که می تواند انجام دهد همان آموزش موتور های جستجو است ، که به عنکبوت موتور های جستجو یاد می دهد در صفحات وب نخزند.توجه داشته باشید که “کشف” و خزیدن” متفاوت هستند.”کشف” وقتی رخ می دهد که موتور های جستجو در اسناد لینک هایی را پیدا می کنند.وقتی موتور های جستجو صفحات را کشف می کنند احتمال اضافه کردن آن به فهرست هایشان 50% است.
Robots.txt امنیت را تامین می کند یا حریم امنیتی را به خظر می اندازد!؟
استفاده از robots.txt برای پنهان کردن فایل های حساس و شخصی یک ریسک امنیتی است.نه تنها ممکن است موتور های جستو این گونه فایل ها را فهرست بندی کرده باشند،این کار شبیه تقدیم کردن یک نقشه ی گنج به دزدان دریایی است!
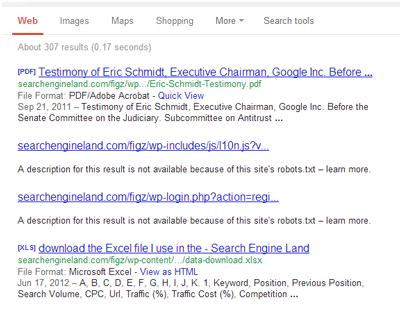
در این جا یک فایل robots.txt از سایت Search Engine Land را مشاهده می کنیم :
User-Agent: * Disallow: /drafts/ Disallow: /cgi-bin/ Disallow: /gkd/ Disallow: /figz/wp-admin/ Disallow: /figz/wp-content/plugins/ Disallow: /figs/wp-includes/ Disallow: /images/20/ Disallow: /css/ Disallow: /*/feed Disallow: /*/feed/rss Disallow: /*?من با استفاده از آن inurl:http://searchengineland.com/figz را جستجو کردم.همانطور که می توانید ببینید فایل هایی را پیدا کردم که مطمئنا راجب ان ها چیزی نمی دانم:
نگران نباشید!اگر به مورد مشکوکی در این سایت برخورده بودم هیچگاه چنین چیزی را با شما به اشتراک نمی گذاشتم!با استفاده از تگ <META> ی Robots فایل ها را به دور از فهرست های جستجو نگه دارید.
چون فایل robots.txt فایل ها را از این فهرست ها پنهان نمی کند ، گوگل و بینگ از یک پروتکل پشتیبانی می کنند که دراین جا متا تگ Robots به کار می آید :...<meta name="ROBOTS" content="NOINDEX, FOLLOW" />متا تگ Robots دو دستورالعمل را در بر دارد :
Index or noindex Follow or nofollowindex or noindex به موتور جستجو می گوید که یک صفحه را فهرست کند یا نه.وقتی Index را انتخاب می کنید ، احتمال فهرست شدن صفحات نصف می شود در حالی که اگر noindex را انتخاب کنید صفحات به هیچ وجه فهرست نمی شوند.
Follow or nofollow به خزنده های وب دستور می دهد که لینک های یک صفحه را دنبال کنند یا نه.این کار شبیه اضافه کردن تگ rel=”nofollow” به هر یک از لینک های صفحه است.nofollow پیج رنک را کاهش می دهد. اجازه دهید پیج رنک تا جایی که امکان دارد ارتقا پیدا کند.در غیر این صورت ممکن است از تعدا زیادی از لینک های مفید بی بهره بمانید.
چنانچه مایلید یک صفحه را از فهرست یک موتور جستجو خارج کنید از کد زیر استفاده کنید :...<meta name="ROBOTS" content="NOINDEX, FOLLOW" />مشکلی که مطمئنا با هردوی این فایل ها خواهید داشت این است که این ها نمی توانند بر دستورالعمل های خودشان فایق آیند.در حالی که گوگل و بینگ مطمئنا به دستورالعمل شما احترام می گذارند،کسی که از Screaming Frog ، Xneu و یا خزنده های وب شخصی اش استفاده می کند می تواند به راحتی دستوزالعمل های Disallow و Noindex را نادیده بگیرد.
تنها نکته ی امنیتی بسیار مهم قفل کردن محتوای شخصی پشت لاگین است.در غیر این صورت ، اگر بیزینس شما در یک مرحله ی رقابتی قرار دارد محتوای شما به مرور زمان تحت تاثیر خزنده های وب قرار می گیرد.
نویسنده : ابوالفضل دانش – سئوتک www.seotech.ir
تاریخ انتشار : 12 آوریل 2013
موضوع : article • بازاریابی الکترونیک • بهینه سازی وب

